Теория баз данных
Язык описания данных иерархической модели
В рамках иерархической модели выделяют языковые средства описания данных (DDL, Data Definition Language) и средства манипулирования данными (DML, Data Manipulation Language).
Каждая физическая база описывается набором операторов, определяющих как ее логическую структуру, так и структуру хранения БД. Описание начинается с оператора DBD (Data Base Definition):
DBD Name = < имя БД>, ACCESS = < способ доступа>
Способ доступа определяет способ организации взаимосвязи физических записей. Определено 5 способов доступа: HSAM — hierarchical sequential access method (иерархически последовательный метод), HISAM — hierarchical index sequential access method (иерархически индексно-последовательный метод), EDAM — hierarchical direct access method (иерархически прямой метод), HID AM — hierarchical index direct access method (иерархически индексно-прямой метод), INDEX — индексный метод.
Далее идет описание наборов данных, предназначенных для хранения БД:
DATA SET D01 = < имя оператора, определяющего хранимый набор данных>.
DEVICE =< устройство хранения БД>,
[OVFLW = < имя области переполнения>]
Так как физические записи имеют разную длину, то при модификации данных запись может увеличиться и превысит исходную длину записи до модификации. В этом случае при определенных методах хранения может понадобиться дополнительное пространство хранения, где и будут размещены дополнительные данные. Это пространство и называется областью переполнения.
После описания всей физической БД идет описание типов сегментов, ее составляющих, в соответстшш с иерархией. Описание сегментов всегда начинается с описания корневого сегмента. Общая схема описания типа сегмента такова:
SEGM NAME = < имя сегмента>. BYTES =< размер в байтах>.
FREQ = <средняя частота реализаций сегмента под одним исходным>
PARENT = <имя родительского сегмента>
Параметр FREQ определяет среднее количество экземпляров данного сегмента, связанных с одним экземпляром родительского сегмента.
Блок связи — РСВ, program communication bloc — описывает связь с одной физической БД по следующим правилам:
DBD NAME = < имя логической БД (подсхемы)> , ACCESS = LOGICAL
DATA SET = LOGICAL.
SEGM NAME = <имя сегмента в подсхеме>,
PARENT =<имя родительского сегмента в подсхеме>,
SOURSE =(Имя соответствующего сегмента ФБД. имя ФБД)
DBDGEN
FINISH
END
Совокупность блоков РСВ образует полное внешнее представление данного приложения, называемое «блоком спецификации программ» (PSB, program specification block).
Рассмотрим пример иерархической БД.
Наша организация занимается производством и продажей компьютеров, в рамках производства мы комплектуем компьютеры из готовых деталей по индивидуальным заказам. У нас существует несколько базовых моделей, которые мы продаем без предварительных заказов по наличию на складе. В организации существуют несколько филиалов (рис. 3.4) и несколько складов, на которых хранятся комплектующие. Нам необходимо вести учет продаваемой продукции.
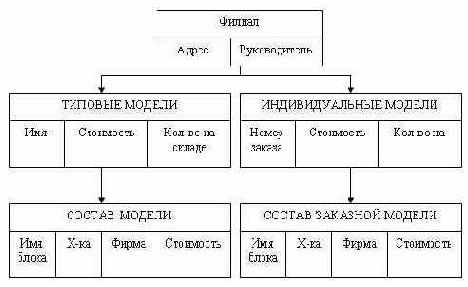
Рис. 3.4. Физическая БД «Филиалы»
Какие задачи нам надо решать в ходе разработки приложения?
Для того чтобы можно было бы принимать заказы на индивидуальные модели, нам понадобится информация о наличие конкретных деталей на складе, в этом случае нам необходимо второе дерево — Склады (см. рис. 3.5).
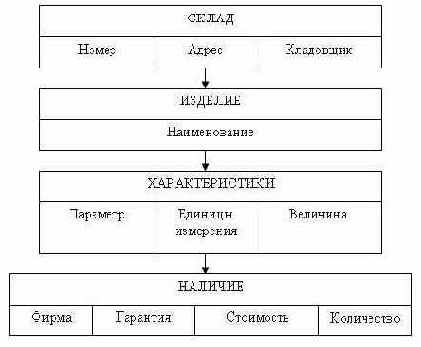
Рис. 3.5. Физическая модель «Склады»